Consideriamo il seguente scenario:
- Vi sono due connessioni aperte passanti per un router con buffer di dimensione infinita e il transmission rate dei link è R.
- è l’arrival rate del router, la quantità di dati inviati da un host della prima rete al router.
- è il throughput del router, la quantità di dati inviati dal router ad un host della seconda rete.
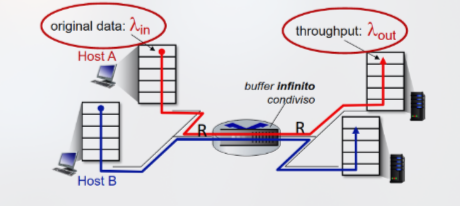
In tal caso, poiché il buffer è infinito ci troviamo in una situazione in cui non sono necessarie ritrasmissioni dovute alla perdita del pacchetto. Di conseguenza, l’arrival rate riesce ad essere equivalente al throughput, corrispondente alla quantità di dati in uscita dal router.
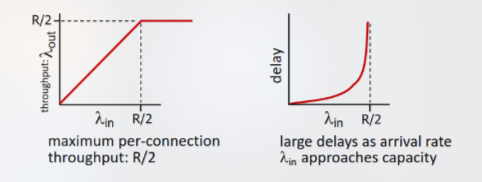
Tuttavia, poiché sono aperte due connessioni passanti per il router, il throughput massimo di ognuna di esse corrisponde a . Inoltre, anche in tale scenario perfetto, man mano che si avvicina a , il delay cresce notevolmente, per via del carico eccessivo sui link stessi della rete.
Nella vita reale, ovviamente, la dimensione dei buffer è finita, implicando che alcuni pacchetti possano andar persi, venendo ritrasmessi dal mittente a seguito dello scadere del timeout. Dato l’arrival rate dei dati originali sommati ai dati ritrasmessi, è necessario sottolineare che:
- Al livello di applicazione, la quantità di dati inviati è equivalente a quella dei dati ricevuti, dunque si ha che = .
- Al livello di trasporto, tuttavia, l’input contiene anche i dati ritrasmessi, implicando che ≥
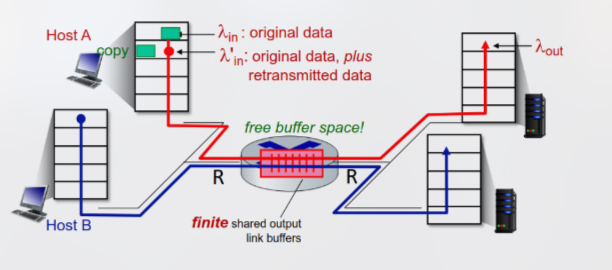
A questo punto, procediamo per assunzioni per studiare come la congestione influenzi l’infrastruttura:
- Idealmente, possiamo assumere che il mittente vada ad inviare i dati solamente nel caso in cui esso sappia che i buffer dei router abbiano abbastanza spazio per ricevere il pacchetto (assunzione perfect knowledge). In tal caso, ci troveremmo in una situazione identica allo scenario perfetto, poiché la rete sarebbe in grado di gestire il carico senza problemi, inviando i dati da un router all’altro al loro arrivo.
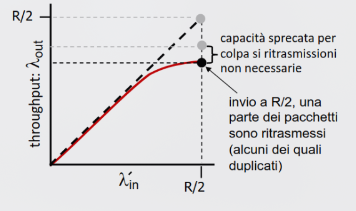
- In uno scenario più realistico, assumiamo che i pacchetti possano essere scartati a seguito di un overflow di un buffer e che il mittente sia a conoscenza perfetta di quali pacchetti siano andati persi, ritrasmettendoli (perfect knowledge parziale). In tal caso, parte della capacità dei link verrebbe sprecata per via delle ritrasmissioni, diminuendo il throughput
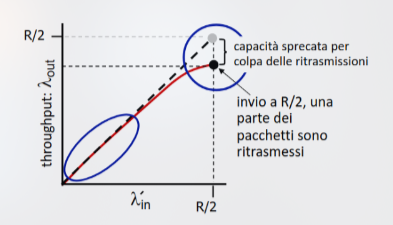
- In uno scenario reale, oltre alla perdita di pacchetti dovuta ad un overflow dei buffer, il timer del mittente può scadere prematuramente, inviando due copie dello stesso pacchetto ritrasmesso (duplicati non necessari). In tal caso, ulteriore parte della capacità dei link verrebbe sprecata per via delle ritrasmissioni non necessarie, diminuendo il throughput ulteriormente
Consideriamo invece ora una rete più realistica in cui tutti e quattro i dispositivi sono mittenti e vi siano più router colleganti le loro reti (rete multi-hop).
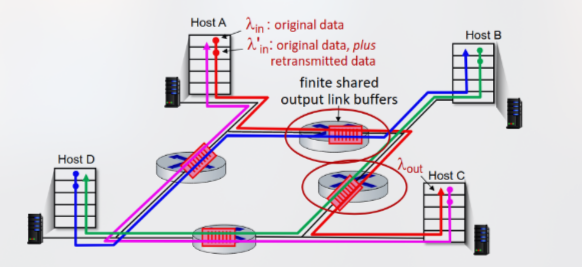
All’aumentare dei valori e del collegamento rosso mostrato in figura, tutti i pacchetti del collegamento blu vengono scartati, poiché il buffer del router viene riempito dai pacchetti del collegamento rosso rinviati, portando il valore a tendere a 0, diminuendo il throughput generale della rete
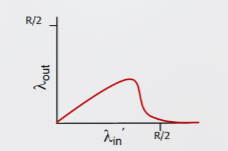
Riassunto
Possiamo quindi riassumere il comportamento della rete nei seguenti punti:
- Il throughput non può mai superare la capacità
- Il ritardo aumenta con l’avvicinarsi alla capacità
- La perdita e ritrasmissione riduce il throughput effettivo
- I duplicati non necessari riducono ulteriormente il throughput effettivo
- Viene sprecata capacità di trasmissione e buffering upstream per i pacchetti persi downstream
Infine:
Infine, utilizziamo tali punti per definire i costi della congestione:
- È necessario un lavoro (numero di ritrasmissioni) maggiore per un dato throughput durante la congestione.
- Il collegamento trasporta più copie dello stesso pacchetto non necessarie, riducendo il throughput massimo ottenibile.
- Quando un pacchetto viene scartato, tutta la capacità di trasmissione upstream e la porzione di buffer utilizzata per esso viene sprecata.